|
Страница 2 из 2 На данный момент примем предположение, что структура правил известна и предпринимается лишь попытка определить вероятности с помощью обучения. Для этого может использоваться подход на основе алгоритма ожидания-максимизации (expectation—maximization — ЕМ), как и при обучении моделей НММ. В процессе обучения мы будем пытаться определить такие параметры, как вероятности правил. Скрытыми переменными являются деревья синтаксического анализа, поскольку неизвестно, действительно ли строка слов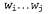 сформирована с помощью правила сформирована с помощью правила 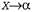 . На этапе Ε оценивается вероятность того, что каждая подпоследовательность сформирована с помощью каждого отдельного правила. Затем на этапе м оценивается вероятность каждого правила. Весь этот процесс вычисления может осуществляться в режиме динамического программирования с помощью алгоритма, называемого внутренним—внешним алгоритмом, по аналогии с прямым—обратным алгоритмом, применяемым для моделей НММ. . На этапе Ε оценивается вероятность того, что каждая подпоследовательность сформирована с помощью каждого отдельного правила. Затем на этапе м оценивается вероятность каждого правила. Весь этот процесс вычисления может осуществляться в режиме динамического программирования с помощью алгоритма, называемого внутренним—внешним алгоритмом, по аналогии с прямым—обратным алгоритмом, применяемым для моделей НММ. На первый взгляд причины продуктивного функционирования внутреннего-внешнего алгоритма кажутся непостижимыми, поскольку он позволяет успешно сформировать логическим путем грамматику на основании текста, не прошедшего синтаксический анализ. Но этот алгоритм имеет несколько недостатков. Во-первых, он действует медленно; этот алгоритм характеризуется временнь/ми затратами , где η — количество слов в предложении; t — количество нетерминальных символов. Во-вторых, пространство вероятностных присваиваний очень велико и практика показала, что при использовании этого алгоритма приходится сталкиваться с серьезной проблемой, связанной с тем, что он не выходит из локальных максимумов. Вместо него могут быть опробованы такие альтернативные варианты, как эмуляция отжига, за счет еще большего увеличения объема вычислений. В-третьих, варианты синтаксического анализа, присвоенные с помощью полученных в результате грамматик, часто трудно понять, а лингвисты находят их неудовлетворительными. В результате этого задача комбинирования знаний, представленных с помощью способов, приемлемых для человека, с данными, которые получены с помощью автоматизированного индуктивного логического вывода, становится затруднительной. , где η — количество слов в предложении; t — количество нетерминальных символов. Во-вторых, пространство вероятностных присваиваний очень велико и практика показала, что при использовании этого алгоритма приходится сталкиваться с серьезной проблемой, связанной с тем, что он не выходит из локальных максимумов. Вместо него могут быть опробованы такие альтернативные варианты, как эмуляция отжига, за счет еще большего увеличения объема вычислений. В-третьих, варианты синтаксического анализа, присвоенные с помощью полученных в результате грамматик, часто трудно понять, а лингвисты находят их неудовлетворительными. В результате этого задача комбинирования знаний, представленных с помощью способов, приемлемых для человека, с данными, которые получены с помощью автоматизированного индуктивного логического вывода, становится затруднительной.
<< В начало < Предыдущая 1 2 Следующая > В конец >>
|